
Introduction
Algorithms and predictive computer systems are increasingly being used in our daily lives to analyse aand predict patterns that emerge from data. Improvements in the technological sophistication, accuracy and efficiency of algorithms today have naturally made the decision to automate appealing for entrepreneurs and as a result, algorithms can be found prevailing far and wide. They incapsulate almost every setting we inhabit; from formal business environments such as within HR departments, where they are used to categorise, filter and sort candidates into prospective groups. To their use in search engines, where they allow for the production of search results that are specific to each individual, and in our favourite music streaming platforms where algorithms are used to personalise playlists and suggest artists that we are yet to discover.
What are Algorithms?
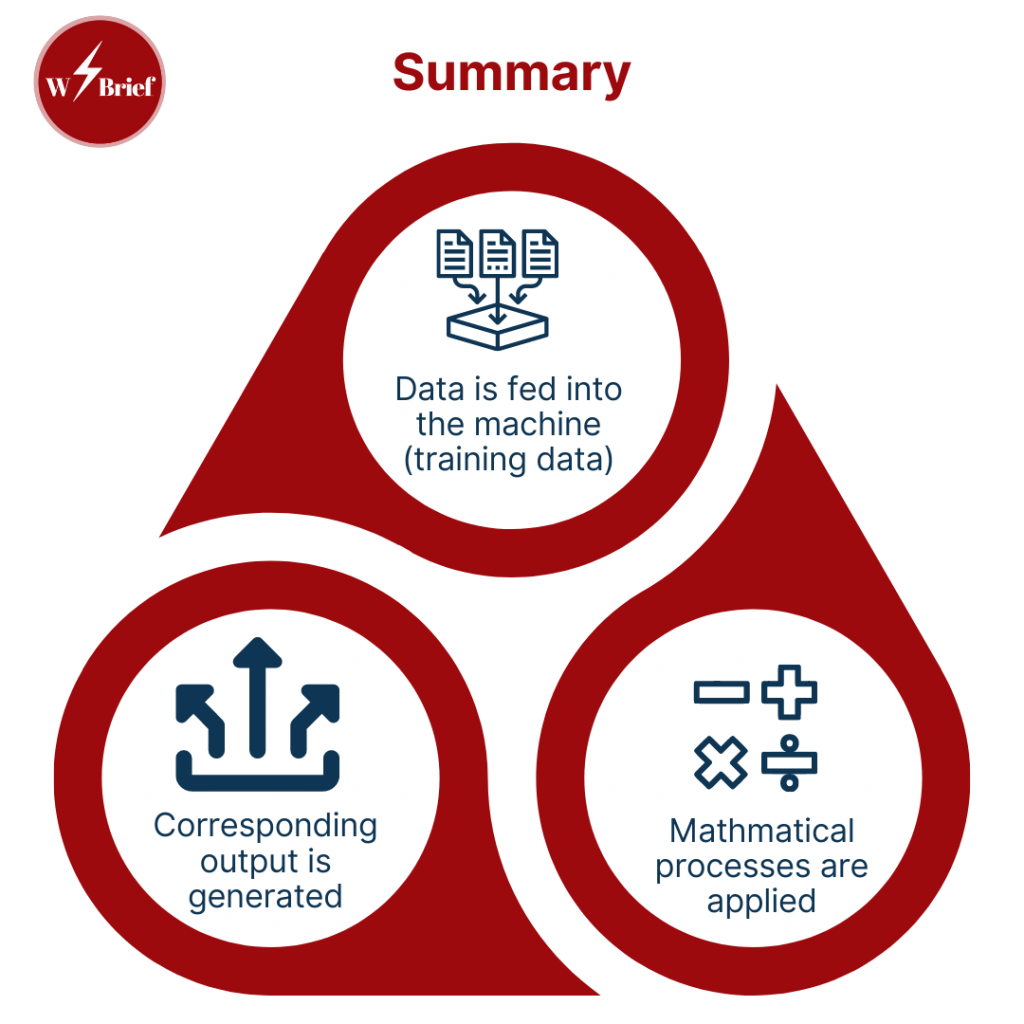
Algorithms are computerised processes that can be used to solve complex problems and predict future outcomes. More specifically, machine learning algorithms are mathematical codes that have been designed by humans to draw inferences from patterns of data and make predictions based on the available information. These are the type of algorithms that are the subject of our attention here. Put simply, data is fed into the machine (training data), mathematical processes are applied, and a corresponding output is generated.
The algorithmic problem – Systematising bias in code
Recent cases where algorithms have been applied in modern settings have put a spotlight on the fact that their effects need to be studied in greater detail. Particularly, as their uncontrolled rolllout can lead to unindented social consequences, if left unchecked by regulators and stakeholders. These examples, which are explored in further detail later on in this ‘Brief’, have revealed that as a result of how they are coded, algorithms are also capable of causing great social harms, by accentuating and systemising the negative biases and implicit assumptions that can exist within societies. This has come to be known as ‘algorithmic bias’ and is used to pick out instances in which certain groups of people are left worse off as a result of the outcomes produced by machine learning algorithms.
In recent times, a typical example of the potential injustices arising from the use of algorithms is the Correctional Offender Management Profiling for Alternative Sanctions (COMPAS). This programme is used by numerous courts in the US to guide sentencing and its purpose is to calculate the likelihood of an offender reoffending. Worryingly, ProPublica also found that the program was creating patterns that were discriminatory towards African Americans; their analysis found that, when controlling other factors, such as prior crimes, age and gender, black defendants were 45% more likely to be assigned higher risk scores relating to the probability of re-offence than their white counterparts. This example, and others like it, in which algorithms have been used to make consequential decisions by those at the decision-making-helm, highlight the vulnerabilities inherent to placing an over-reliance on automated systems.

What we’ll cover
In this article we will begin by first outlining algorithmic bias in greater detail, and in doing so, highlight two of its most common manifestations; pre-existing bias and feedback loop bias. To make sure you have a clear conception of how algorithmic bias works in the real-world, we will move on to focus our attention on Amazon’s AI recruiting tool and why the results it was producing forced Amazon to remove it. We will then move on to take a look at the relevant law surrounding algorithmic bias, as well as the social context in which it sits. Finally, our focus shifts to the future, and how we should aim to move forward with the use of algorithmic processes in light of our awareness of the possibility of negative outcomes.
- Algorithmic Bias, What is it?
- Recruitment Case Study
- The Legal Context
- The Social Context
- Outlook
- Takeaways
Algorithmic Bias, What is it?
Algorithmic bias refers to the systematic and repeatable errors programmed into computer systems that consequentially create unfair outcomes, e.g. privileging one group of users/customers over another. If left un-checked, this can have disastrous effects for society’s future development.
Algorithmic bias can manifest itself in many different ways, with each having a varying and unique impact on the degree of disenfranchisement and exclusion its victims will inevitably face. Below, the two most prominent types of algorithmic bias have been denoted and briefly explained:
1. Pre – Existing Bias
This occurs when the training data, which is the data that is used to train an algorithm, reflects the implicit assumptions and biases that are held in society. For example, an investigation carried out by DW, the German broadcaster, using 20,000 images and websites, uncovered hidden biases in algorithms used by the search engine Google. They showed that image searches using the expression “Brazilian women” were more likely to produce indecent results when compared to the results found for the expression “American women”.
2. Feedback Loop Bias
An algorithm is also capable of influencing the data that it receives through positive feedback loops. Simply put, this means that the algorithm amplifies what has happened previously. This is the case regardless of whether the amplification is good or bad. Cases of this have been uncovered in the police’s use of AI in predicting the incidence of crime in certain areas. Once an area is identified, more police are sent to this area which often results in an increase in the crime rate and this information is then fed back into the algorithm; and the cycle repeats.

It is important to note at this point that, despite the growing intrigue in algorithmic bias, the relevant evidence is usually difficult to obtain and this is restricting academic research into this area. The algorithms deployed in business are often proprietary and the result of large amounts of effort, investment and research. This means that the secrets behind how these algorithms work are often closely guarded. As such, most attempts made by external researchers to investigate potential bias issues are often left begging, without little cooperation from manufacturers. But with increasing social pressure and awareness of algorithmic bias, high-profile companies, such as Twitter, have recently tried to tackle this issue by holding competitions to identify and address algorithmic bias.
- Protected: Empowered Leadership: The Transformative Power of Belief and Faith
- Legal Gen AI Unleashed – A Practical Guide to Harnessing Artificial Neural Networks and the Power of Time-Based AI Prompts
- Protected: Balancing Tech with Critical Thinking: How Professional Parents Can Prepare Their Children for an AI-Powered World (Expected Release date: 08.10.2024)
- Current Awareness: Harnessing Quantum Computing: Transforming ESG for a Sustainable Future.
- AI WAVES: Web 3.0, Blockchain and Cryptocurrencies [VIDEO]
Recruitment Case study – AMZN.O

As is hopefully becoming clear, the influence of algorithms in decision making is widespread across all industries, from the financial services to local government. One particular area in which the use of algorithms is becoming increasingly prevalent is in the recruitment process; it was estimated in 2016 that around 72% of CVs in the US were never seen by humans.
Let us take a closer look at the use of algorithms in this context by analysing the somewhat recent Amazon recruitment case study. In 2014, through systems developed by AMZN.O, Amazon’s in-house machine learning specialists, the company began to use computer programs to review job applications. Automation has been a significant part of Amazon’s rise to the top of the e-commerce industry and was therefore inline with its prior course of business developments.
However, from as early as 2015 it was already becoming clear that candidates were not being rated in a gender neutral way, specifically for technical posts such as ‘software development’ positions. What quickly came to light was that the model had learnt to assign negative scores to the word ‘women(s)’ when it was used to describe extracurricular activities. The reasoning being that the model had been trained on the CV’s of historically successful candidates for these sorts of positions at Amazon, and these previously successful candidates were predominately male.
“Algorithmic Bias refers to the systematic and repeatable errors programmed in to computer systems that consequentially create unfair outcomes i.e Such as privileging one group of users over another”
Therefore, we are able to conclude, at least in part, that this is an example of pre-existing bias. This is because the model had recognised the male domination of certain job roles at amazon and made its predictions on the basis of this information. The debate that therefore ensues focuses on whether algorithmic screening can be employed to counter these biases, both explicit/conscious and implicit/unconscious, that human recruiters often fall guilty of.

The Legal Context
- The Equality Act 2010
- EU Generat Data Protection Regulation
- Data Protection Act 2018
There are a few fundamental pieces of legislation in European and UK contexts of relevance to the issue of algorithmic bias. Of particular importance is the Equality Act 2010, which picks out nine ‘protected characteristics’ (see also how these human rights appear again in the European Commissions framework for trustworthy AI covered here) that demarcate illegal discrimination. These are: age, disability, gender reassignment, marriage and civil partnership, pregnancy and maternity, race, religion or belief, sex and sexual orientation.
On first impressions the Equality Act appears to present a clear cut guide for tackling algorithmic bias as we can hold humans accountable for the discriminatory decisions that they make. For an algorithm to be discriminatory in some way it must therefore have been programmed by some human to this effect; allowing accountability to be easily deduced. However, in practice things become a little hazy. For example, an algorithm can be explicitly programmed to exclude data concerning biological sex, but where this data strongly correlates with some other attribute, such as occupation, the algorithm may still end up producing sexist outcomes.
On the other hand, the risks that the uses of AI pose can be situated against some long-established legal principles and responsibility models. For instance, intention and negligence are important elements of civil and criminal cases. Considering the former, proving intent will likely require focusing on the individuals that intentionally developed and deployed a programme for malicious purposes. Furthermore, where predictions that programs make result in the causation of harm, and in those instances where a developers intent is absent, there could still be a legal question whether there was reasonable effort to foresee such harm.
Another approach that would negate the need for intention, would be to regulate algorithmic disputes through a ‘no-fault’ strict liability scheme. Under this, the very act of unfair discrimination by an algorithm would constitute enough evidence for its creators to be proven to be at fault and liable for the actions of their creation; unforeseen or otherwise. Unfortunately however, proving discrimination for the injured parties can be difficult. Especially, as we have previously covered, in situations when a CV has been unfairly filtered out by a sorting algorithm before the interview stage. In this situation affected parties will often not realise they are victims of such bias until many years later.
Finally, the EU General Data Protection Regulation (GDPR) and the Data Protection Act 2018 are pieces of legislation that include provisions aimed at providing effective legal safeguards such rights of transparency of explanation and of contestation for fully-automated decisions that process personal data.

The Social Context – Algorithmic discrimination
The main social implication of algorithmic bias is discrimination and the phrase ‘algorithmic bias’ is often used as a synonym for ‘algorithmic discrimination’. Discrimination is said to take place when one arbitrary group of people is, with no justified reasons, treated worse than the rest of the population.
The most significant concern for many is that not only are we seeing biases reflected in new automated decision-making processes, but that they are also being compounded. This exacerbating existing societal struggles with discrimination and inequality. Furthermore, some feel that the automation of such processes is resulting in accountability becoming blurred.
Encouragingly, NGOs are doing some very important work in order to illuminate the risks that machine learning systems present to human rights and liberties, including Amnesty International, Access Now, Human Rights Watch and Privacy International.
Outlook – The need for a standardised approach for detecting and measuring algorithmic bias
We must acknowledge the fact that the biases that we are uncovering in algorithmic decision-making processes are most likely the product of the implicit assumptions and negative associations of the past, alongside those that still exist in society today.
It seems obvious that a clear and standardised method for detecting and measuring algorithmic bias is essential at this moment. This is important as it is crucial that we develop an understanding of whether or not algorithmic bias is producing results that are worse than those biases that pre-exist them in society. It is only at this point that we may determine when and in what contexts the use of algorithms is producing a net-loss for society; to me, at this point there use would be hard to justify.
There also needs to be a focus on mitigation in the first instance which will likely be most effectively achieved through regulation. Following on from the point made above, until we deepen our understanding of what biases are at play this will be very difficult. Whether limiting the uses of algorithmic systems until this has been ironed out is the most appropriate way forward is a very contentious but important debate at present.
Article Takeaways
- Algorithmic bias often reflects the negative biases and implicit assumptions that already exist in society.
- The opaque nature of machine learning algorithms is limiting our ability to identify and address the potential biases.
- Increased legal scrutiny will be required in order for our current legal principles to appropriately apply in the AI age.
- The current trend of self-regulation should be left behind in order to prevent the sidelining of the law and legal institutions.
For more on automation and algorithms, see here

“The most significant concern for many is that we are not only seeing biases reflected in these new automated decision-making processes, but that they are also being compounded; exacebating discrimination and increasing inequalities.”
— Aidan Nylander,
Author
- Protected: Empowered Leadership: The Transformative Power of Belief and Faith
- Legal Gen AI Unleashed – A Practical Guide to Harnessing Artificial Neural Networks and the Power of Time-Based AI Prompts
- Protected: Balancing Tech with Critical Thinking: How Professional Parents Can Prepare Their Children for an AI-Powered World (Expected Release date: 08.10.2024)
- Current Awareness: Harnessing Quantum Computing: Transforming ESG for a Sustainable Future.
- AI WAVES: Web 3.0, Blockchain and Cryptocurrencies [VIDEO]
Be the first to comment